Hadoop Project
✏ MapReduce 패러다임을 사용하여 매우 큰 데이터 세트의 분석 및 변환을 위한 프레임워크와 분산 파일 시스템(HDFS) 을 제공 -> MapReduce는 클라우드 프로그래밍 모델이자 runtime system
- data 분할은 물론 수 많은 host에 computation도 분산 실행
- 근접한 데이터에 병렬로 application computations(보통 task를 의미) 실행
-> 근접한 데이터 : data locality의 관점 - 하둡 클러스터는 commodity server를 추가하는 것 만으로 computation capacity, storage capacity, IO bandwidth 확장 가능 -> scale out architecture
✏ MapReduce Paper
- MapReduce는 모든 computation을 map과 reduce라는 두 개의 함수로 표현 -> programming 할 수 있는 범위가 좁음
- 대용량의 데이터 생성/처리를 위한 구현 결과물(framework)
- USER : map/reduce를 구현해줘야 함 -> MapReduce framework는 사용자가 정의해준 map과 reduce func.을 적용하는 역할만을 수행함
MapReduce 개발 배경
✏ MapReduce 개발 이전
- Google에선 굉장히 큰 규모의 raw data 처리를 위해 특수 목적형 computation 수백개를 개발
- raw data : crawling 된 문서, 다양한 종류의 derived data 처리를 위한 Web request log 등
- 개념적으로는 굉장히 어렵지 않은 computation이지만 input data가 굉장히 크고 수천/수백 대 이상의 machine에서 분산되어 실행 되어야 함(합리적인 시간 안에 결과물을 내놓기 위해)
- 분산 컴퓨팅으로 overhead가 커짐 : distribute 하는 순간 failure가 가장 큰 문제, loadbalancing도 문제
- so, runtime system이 이걸 알아서 해줬으면 좋겠는데? 라는 생각을 하게 됨
- MapReduce의 개발로 사용자는 이제 MapReduce가 제공하는 programming model에 맞게 적절히 Map/Reduce func.을 구현해주고 key-value pair를 어떻게 정할지, 원하는 연산 수행을 어떻게 할지만 고민하면 됨
✏ MapReduce : 대규모 dataset 처리/생성을 위한 programming 모델이자 연관된 구현체
- simple computation을 표현하기 위한 새로운 추상화(단순한 형태의 computation을 어떻게 더 잘 표현할지)
- parallelization, fault tolerance, data distribution, load balancing 등 분산처리로 인해 발생하는 messy한 문제들을 숨겨줌 = MapReduce가 알아서 해줌
- map/reduce에서 영감을 받아 Lisp이나 많은 다른 functional 언어에 존재하는 원시 요소를 줄여줌
- USER가 Map operation을 정의해 적용하면 input data인 logical record의 intermediate key-value pair set 계산
- USER가 Reduce operation을 적용하면 같은 key를 공유하는 value들의 리스트를 받아 어떤 형태로든 combine 연산 수행
- 반드시 같은 key값을 공유하는 모든 value들은 하나의 reduce에게 전달 되어야함
※ reduce가 두개 이상일 경우 MapReduce system이 같은 key를 공유하는 value를 쪼개지 않도록 - map과 reduce 단계 사이에 shuffling 존재 : 같은 key를 공유하는 모든 value들을 묶어줌
Programming Model
✏ Computation : input엔 key-value pair 집합 사용, output엔 key-value pair 집합 생성
- 사용자가 작성한 Map은 input pair를 받아들여 output pair를 생성
- MapReduce는 intermediate key가 같은 값을 공유하는 모든 value를 묶어줌
- ※ reducer가 2개 이상일 수 있기 때문에 같은 key에 대한 value들의 집합이 쪼개지지 않도록
- ※ map은 HDFS라는 하나의 큰 파일을 block 단위로 쪼개 저장 -> block 하나하나 당 mapper가 뜬다고 생각하면 됨
- ※ input split == HDFS block size, 즉 하나의 block에 하나의 mapper 적용
- mapper들은 사실 여러 block들이 흩어져 있는 여러 노드에서 동시다발적으로 실행되기 때문에 실행중에 생성되는 intermediated k/v pair들을 mapreduce가 grouping 해줌
- 사용자가 작성한 Reduce는 intermediate k/v pair들의 리스트를 받아 merge, 더 작은 값의 집합을 생성
- (ex : wordcount에서 count를 다 더해 특정 단어가 몇 번 사용 되었는지)
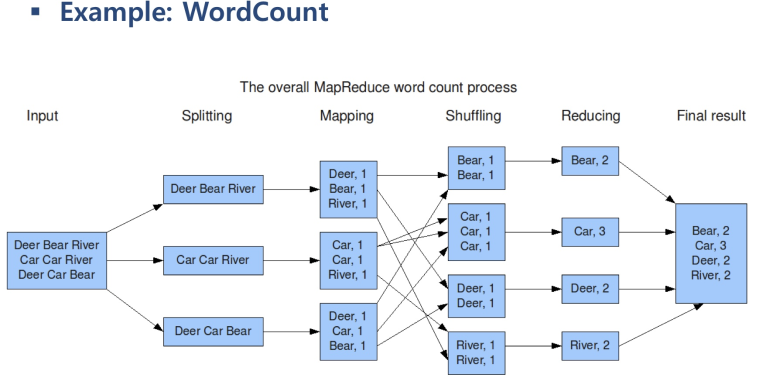
- 언제나 input data는 무지막지하게 클 수 있다 가정 -> block 단위로 쪼개 저장/처리
- Splitting == input-split
- Mapping 단계에서 모든 mapper의 작업이 끝나야 다음 단계로! 동시다발적, 독립적 시행!
- 여기선 mapper가 3개! 자기가 담당하는 input-split을 읽어들여 사용자가 정의한 map함수 적용
- map/reduce/main 총 3가지를 작성해 실행하면 input data가 아무리 커도 MapReduce가 알아서 일련의 과정을 거쳐 같은 key를 공유하는 value들의 집합을 다시 reduce에 넣어줌, reduce에서 나온 결과는 다시 HDFS에 저장됨
Implemetion
google MapReduce 동작 방식
✏ Execution Overview (Google MapReducee)
- Map 호출은 input data를 M개의 input-split으로 partitioning -> partition 개수만큼 map class 생성
- 즉, Mapper의 개수는 input data의 크기에 비례(어차피 같은 크기의 block으로 분할하기 떄문)
- input split은 서로 다른 system에 의해 병렬처리 될 수 있음
- input-split : 하나의 큰 데이터를 처리할 때 얼만큼 잘라서 mapper를 적용시킬지 의미
- parallel하게 서로 다른 machine에서 동시다발적으로 mapper가 실행 될 수 있다
- Reduce 호출은 intermediate key space를 R개로 분할
- reducer가 2개 이상이 되면 여러가지 생각을 해야함
- ex) R = 2일때 wordcount에서 reduce를 실행하면 car/bear은 reducer 1에 deer/river는 2로 보냄
- 다만, intermediate k/v pair 숫자 자체가 balancing 되는 것은 X
※ input data에 의해 reducer 1의 일이 2의 일보다 엄청 많을 수 있음 -> 하지만 이건 미리 예측 불가
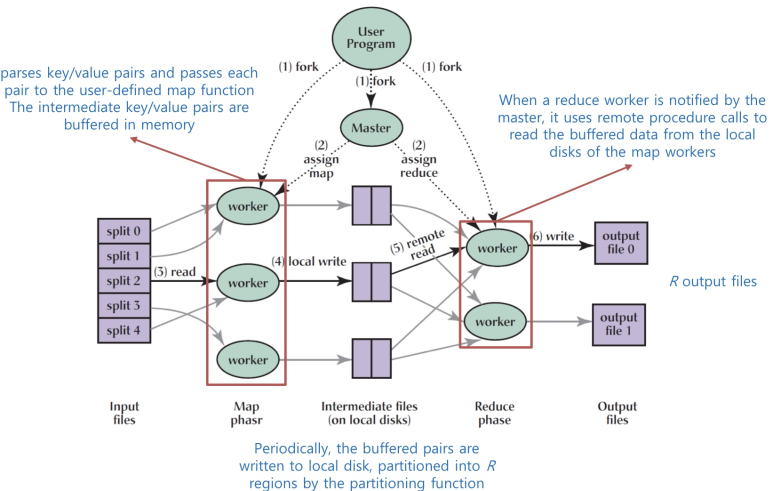
- master (job tracker) : mapreduce 관장 / worker(task tracker)
- k/v pair를 parsing해 사용자가 정의한 map 함수로 보내줌. worker가 mapper를 통해 하나의 input- split를 처리하며 나오는 intermediate k/v 같은 경우 일단 메모리에 buffering
- 주기적으로 buffering된 pair들이 localdisk에 저장, R개의 region으로 parition되어 있음
- reduce worker가 master로부터 mapper가 완료됐다는 notification을 받음 -> 각 worker가 담당하는 partition을 가져가라고 master가 시킴 -> 각각 reduce worker가 mapper가 사용됐던 worker에 remote procedure을 통해 contact해 해당 localdisk에 저장되어 있던 data를 끌어감
- 결과적으로 reduce의 개수만큼 output 파일이 생성됨

- reducer의 개수만큼 partition을 논리적으로 쪼개는 건 맞지만 실제 특정 partition에 data가 아예 없을 수도 있음 -> mapper가 담당하는 input-split data가 어떻게 구성되어 있느냐에 따라 다름
- shuffling 단계가 MapReduce에서 가장 복잡하고 가장 오버헤드가 큼(네트워크 통신이 많이 일어남)
Fault Tolerance
✏ Handling Worker Failures
- master가 주기적으로 worker들에게 ping을 보냄 -> node가 죽었나 살았나 확인
- 일정시간 무응답 시 죽었다고 판단
- failed worker에 의해 완료된 모든 map task가 reset되고 other worker에 의한 scheduling 자격 부여
- 실패한 경우 완료된 map task가 다시 수행됨
- failed machine의 local disk에 output이 저장됨
- ※ 각각의 mapper가 생산한 중간 결과물은 mapper가 실행되는 노드에 localdisk에 저장되어 있음
- ※ 결과적으로 failed machine은 접근 불가이므로 할당됐던 모든 task가 재실행 되는 것
- reduce작업이 완료된 경우 재실행 될 필요 없음
- output이 global file system(HDFS)에 저장됨 : 안정적으로 접근 가능
- ※ Map task는 HDFS에 저장하면 낭비임 : map task 이후 중간 결과물은 aggregation등으로 사라짐
✏ MapReduce는 대규모 worker failure에 탄력적임(고장감내/회복가능)
- 개발자는 messy detail에서 자유로워짐(가장 큰 장점!)
Locality
HDFS block 배치가 도움이 됨
✏ Network bandwidth : 상대적으로 부족한 리소스 -> 아껴써야 하지 않을까? 가 디자인 철학
- input data가 machine의 local disk에 저장된다는 이점을 활용
✏ Moving computations close to the data
- master는 maptask를 얘가 필요로 하는 input-split data를 실제로 소유하고 있는 machine에서 allocation하기 위해 최선의 노력
- 실패하면 그 노드가 바빠서 작업을 더 받아들이지 못한 것일 수 있으니 그나마 input data에 가까운 쪽에 배치하고 싶어함
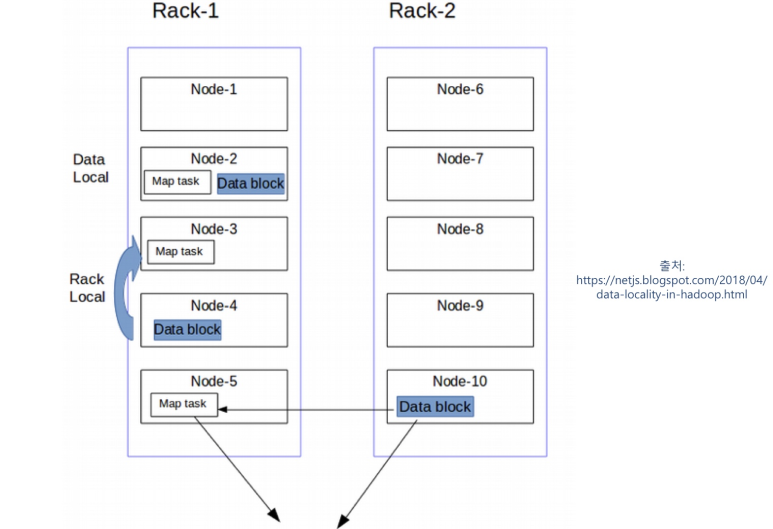
- Data Local : best case, 네트워크 통신 필요 X
- Rack Local : best case 실패, 불가피하게 하나의 rack에서 다른 노드에 있는 것 copy
- ※ MapReduce의 data locality 보장을 위해 HDFS의 block 배치가 도움이 됨
- 하나의 노드가 똑같은 block에 대한 application을 두 개 갖고 있지 않는다
- 같은 data block에 대해 하나의 rack에는 2개 다른 rack에 한 개 저장 : rack 하나가 완전히 나가는 경우 대비
Experience in Google
✏ Large-Scale Indexing
- MapReduce의 가장 중요한 용도 중 하나
- production indexing system의 완전한 재작성
- indexing system을 위해 MapReduce를 사용하는 것의 이점
- indexing code가 훨씬 간단하고, 작고, 이해하기 쉬움
- fault tolerance, distribution, parallelization이 숨겨짐
- MapReduce의 performance가 충분히 좋음(빠름)
- indexing process가 운영하기 훨씬 쉬워짐 : 다양한 문제가 운영자의 개입 없이 MapReduce에 의해 자동 해결
- indexing code가 훨씬 간단하고, 작고, 이해하기 쉬움
Hadoop : MapReduce + HDFS
아래 그림은 하둡 1.x. ver

- namenode와 job submission node는 하나로 운영하기도 나눠서 운영하기도 함
- TaskTracker와 datanode daemon은 함께 있어야함
- TaskTracker가 없을 경우 : JobTracker가 map/reduce task를 아예 보낼 수 없음, 즉 task 실행의 주체가 없는 상황 == slave node(물리적 node 의미)가 없는것과 같음
- datanode daemon이 없는 경우 : HDFS에 저장된 data를 가져 올 방법이 거의 없음 -> task tracker가 data 처리를 위해 언제나 다른 datanode에서 data를 copy 해와야 함
Hadoop MapReduce (ver 1.2.1)
✏ JobTracker
- cluster에 있는 특정 node들에게 MapReduce task를 farm out 함 -> data locality 구현 주체
- input data를 갖고 있는 node에 map task를 가져다줌
- 아니면 적어도 같은 rack에 있는 node에서 map task를 실행하도록
- Hadoop MapReduce 서비스의 failure 지점
- JobTracker가 down되면 모든 job이 halting : 큰 로직에서는 많은 job이 발생하고 job tracker의 부담 또한 증가, 오버헤드가 발생 -> 즉, HW가 어렵다 : hadoop2에서 yarn이 나옴
- Steps of MapReduce job Procissing
① client application이 MapReduce job을 job tracker에 제출
② JobTracker가 namenode와 contact (map task가 요구한 data와 최대한 가깝게 스케줄링 하기 위해)
③ JobTracker는 namenode로 부터 위치를 받아 input data에 제일 가까이 있고 가용 slot이 있는 Task
Tracker를 찾음
※ TaskTracker는 mapper/reduce를 몇 개 돌릴 수 있는지 이미 configuration 되어있음(고정된 개수의
slot)
④ JobTracker가 선택된 TaskTracker들에게 작업을 던져줌
⑤ TaskTracker 노드들은 모니터링 되며 heartbeat signal을 주고 받고 충분히 자주 보내지 않으면 failed
됐다는 것을 알고 원래 해당 TaskTracker가 하던 작업을 다른 TaskTracker에게 스케줄링함
⑥ TaskTracker는 작업 실패시 JobTracker에게 알림 -> JobTracker는 작업을 다른 곳에 resubmit, 특정
레코드를 피해야 할 것으로 표시, 신뢰할 수 없는 TaskTracker를 블랙리스트에 추가 할 수도 있음
⑦ 작업이 완료되면 JobTracker가 상태 업데이트
⑧ client application이 job tracker에서 관련된 정보를 가져올 수 있게 됨

- 3번 과정에서 job resource는 보통 mapper와 reducer 클래스를 모두 포함하고 있는 자료 같은 것
- 이걸 HDFS에 올려놔야 나중에 map/reduce task를 실행할 수 있음 -> 어디서나 접근 가능하도록
- 8번 과정에선 3번 과정에서 저장했던 자료 파일을 가져와야 map/reduce task를 실행 할 수 있음
- 실행 : TaskTracker가 child JVM을 통해 사용자가 정의한 map/reduce 함수를 적용하는 과정
✏ TaskTracker
※ task 실행을 위해서 slot이 있어야 하고 data locality를 고려해야함
- JobTracker에서 Map, Reduce, Shuffle 등을 받아 실행하는 역할
- 모든 TaskTracker는 slot 집합으로 구성(static)
- 각각의 TaskTracker가 받아들일 수 있는 mapper/reduce의 개수가 사전에 구성 돼 있음
- static 해 발생하는 문제 : 하둡 클러스터가 hoogeneous하다고 가정-> 클러스터를 구성하는 노드의 HW spec이 비슷하니 균등하게 분할 해 같은 수의 mapper/reduce를 처리하면 되겠네 라는 naive한 생각에서 시작 -> 시간이 지나며 각 노드의 computing power가 달라지기 시작하고 다양한 framework가 들어오며 slot 기반의 자원관리가 좋지 않다는 것을 깨달음
- 실제 작업 수행을 separate JVM 프로세스 생성
- map/reduce task가 실행되다 죽더라고 TaskTracker 자체에는 별로 영향을 미치지 X
- 생성된 프로세스 모니터링, 출력/종료 코드 캡처 : JobTracker에게 보고
- 프로세스가 끝나면 성공적으로 끝나든 에러가 발생하든 JobTracker에게 결과를 알리고 어떤식으로 조치할 지 요청
- JobTracker에게 heartbeat 메시지를 보내 TaskTracker가 아직 살아있다고 알림
- 가용 가능한 slot의 개수도 알려줌
'학부 > 클라우드 컴퓨팅' 카테고리의 다른 글
| 클라우드(클라우드 컴퓨팅)의 기본 개념, 서비스 형태, 운용 형태 (0) | 2022.11.23 |
|---|---|
| 빅데이터의 기본 개념 (0) | 2022.11.21 |

댓글